
IDE For LLMs
Build, Fine-tune and Deploy like never beforeEngineering
Announcing Zerve - The Next Generation Data Science Development Environment
Release of Zerve v0.1 Data Science Development Environment
Written by: Phily Hayes, January 30, 2024

Content of the article:
- Our Mission
- The Trend Over the Last Decade
- The New Zerve Architecture
- Benefit: Stability
- Benefit: True collaboration
- Benefit: Language Interoperability
- Benefit: Seamless multi-processing
- Benefit: Persistent artifacts
- Start building in Zerve today!
Share this article:
Today we’re excited to be unveiling something totally new in the world of data science and AI development. We’ve been building in stealth for the last two years, and we're finally opening the door to let the world in.
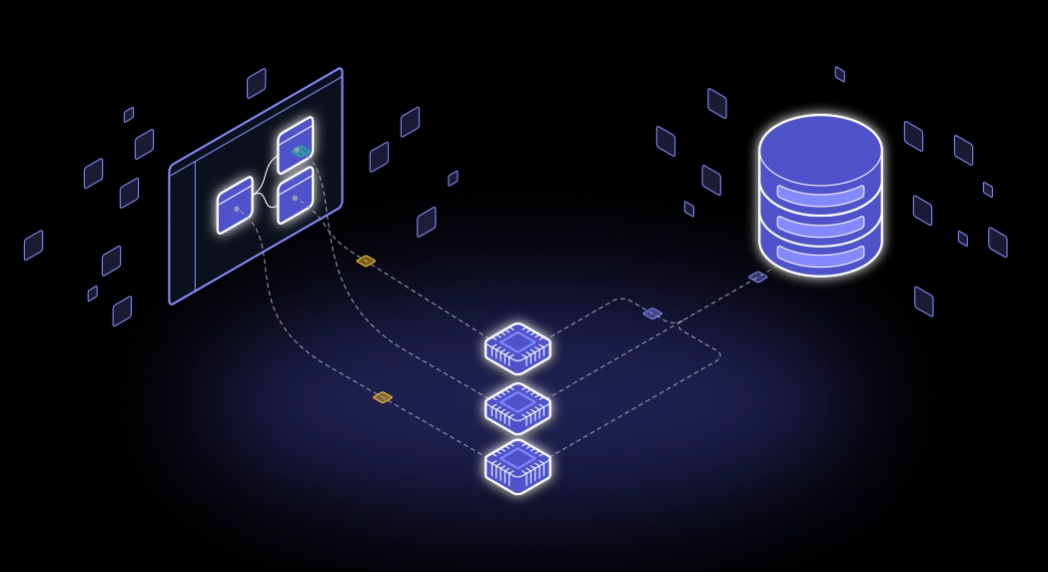
Our Mission
Our mission at Zerve is to Elevate the impact of Data Scientists. Why? A few reasons.
- My two co-founders Greg & Jason, two PhD level statisticians, are two of the smartest people I know. They have tales of not being able to get their organization's AI initiatives over the line, or crazy inefficiencies in the process while doing so. They have lived the problems. Teams separately working on local notebooks and meeting twice a day to share findings, and emailing / zipping the latest data to other team members. Inefficient, and not fit for purpose in a world that will demand impact from Data Science teams like never before.
- We’ve spent 100s of hours interviewing ‘Code-First Data Users’ who not only confirmed the efficiency losses we knew, but shedded light on even more. We heard all too often that the Data Scientist's impact was set up to be distinctly unimpactful, a screenshot of a Matplotlib chart on a PPT, an uninspiring Data App, or a handover that resulted in a complete re-coding of the original work.
- We believe to truly unlock the opportunities in AI, LLMs and Data Science over the next decade, expert Data Scientists will be the difference makers, and we set out to build a platform that puts Data Scientists at the heart of the innovation.
The Trend Over the Last Decade
The trend over the last decade has been moving towards low-code/no-code solutions for developing data science. Software vendors have developed a dizzying variety of tools that supposedly allow anyone to train sophisticated models and to interact with their data without needing to write code. It has become obvious to anyone who has actually ever deployed a Data Science project though, that these tools are wildly inflexible and therefore entirely unsuitable for doing anything serious. That’s because 100% of data science projects require code, and that’s why Zerve is built for code first data teams. The introduction of Large Language Models presents the opportunity to help build data solutions even further, however our thesis remains the same, these tools need to be used in addition to the knowledge of a code-first data user who is building the solution. We believe these tools will lead to even more code-first data teams, not less.
The coding toolkit for data, though, is problematic to say the least. Data engineers might be working in snowflake or DBT or some other tool where they write SQL. Passing the data along for analysis, the data scientists typically start in a notebook environment, like Jupyter. The problem with notebooks is that they are brittle. Jupyter was developed by academics to be used as a classroom scratch pad. Jupyter is wonderful for exploring data, but it’s undeployable - meaning that if you’re working on something serious, you’ll eventually need to move to an IDE, like PyCharm or VSCode at some point.
Because of the architecture of notebooks, it’s very easy to get them into a bad state. In the example below, by running the cells of the notebook too many times, it’s easy to get into a state where 1+1=7. That’s why every modern notebook has a “restart kernel” button. Because they all operate with a global variable space that makes production work with a notebook infeasible and dangerous.
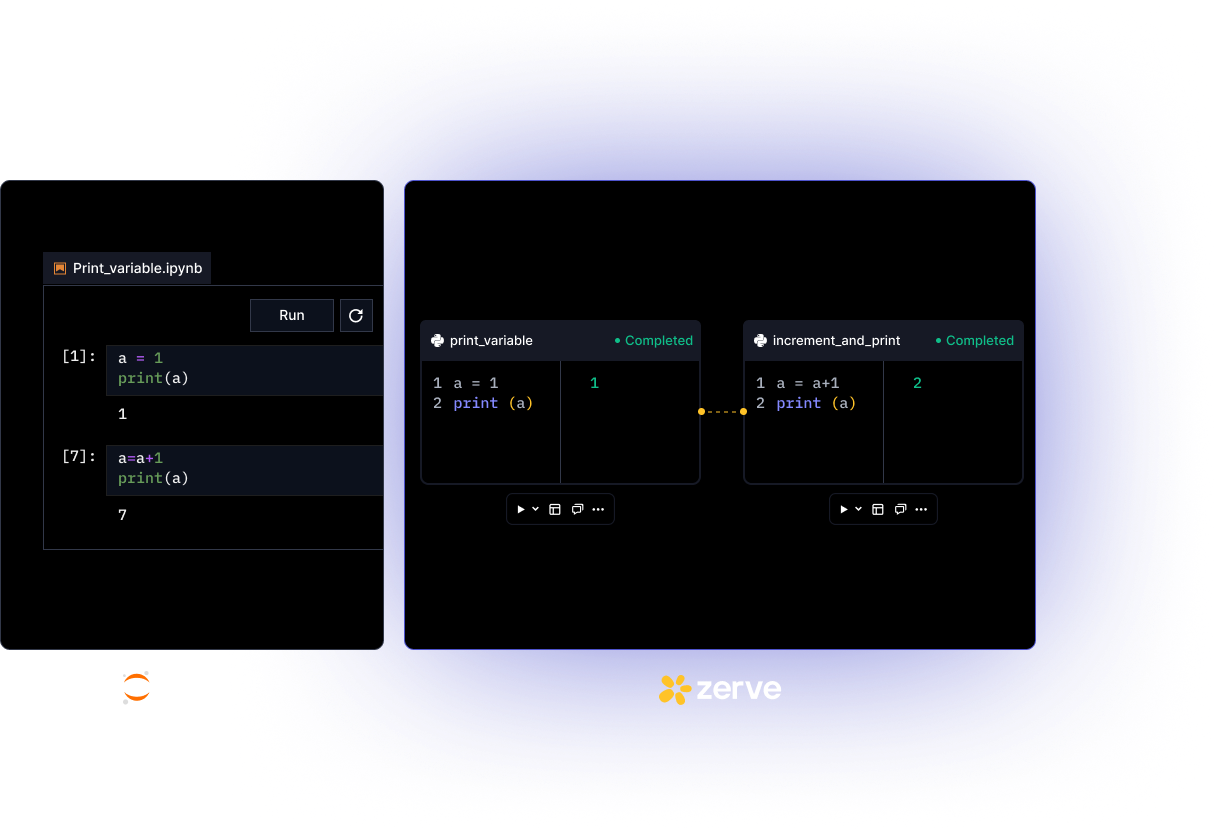
Since notebooks can’t handle production workloads, developers turn to scripting environments or IDE’s. These tools are terrific for writing stable code, but they were built for software developers and so they’re unsuitable for data exploration. Maybe that’s why the Jupyter plug in for VSCode has been downloaded over 40 million times.
Given the importance of where AI is at a board level, it's utterly surprising that this toolkit is involved in every serious data science project, at some point or another.
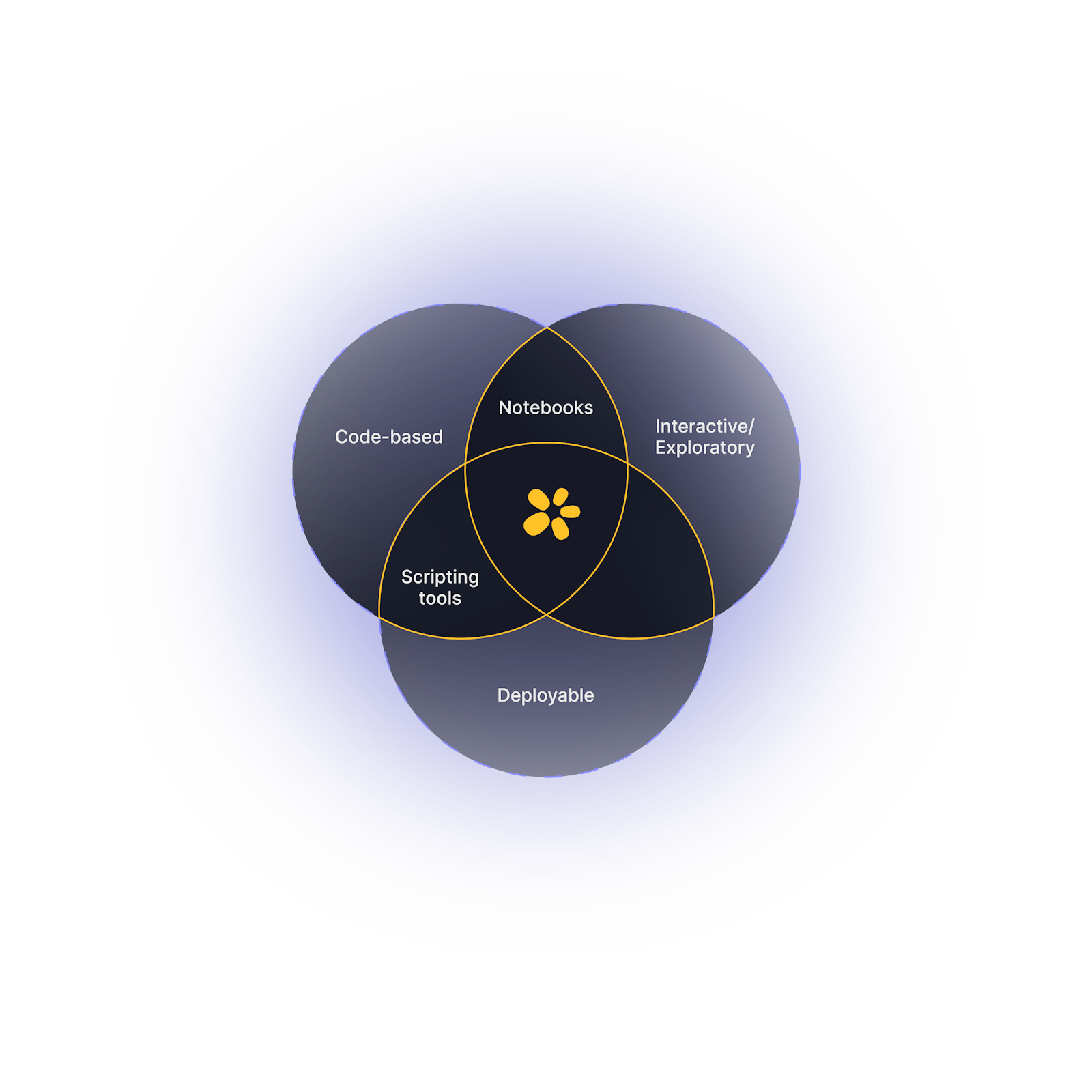
That’s where Zerve comes in. Zerve is the first Data Science Development Environment of it's kind, built upon a novel architecture, giving you all the benefits of interactive analysis with notebooks without sacrificing the stability of a scripting environment. With Zerve you can explore, build, and deploy all from the same environment. To truly do this, the underlying architecture had to ensure stability. Let's explore that.
The New Zerve Architecture
The foundation of Zerve’s revolutionary architecture is separating storage from compute. In Zerve, code is organized as a DAG, and code executes from left to right. Each code block inherits the state of the preceding blocks. When you run your code in Zerve, Zerve launches serverless compute to execute your code. The state of the code block after code execution is then cached, serialized, and stored on disk so that it’s ready to be inherited by the next code block. This architecture changes the development dynamic in data science, and produces incredibly important benefits.
Benefit: Stability
There is no restart kernel button in Zerve. You read that correctly. That's because there is no way of getting your Zerve canvas into a bad state, so there is no need to ever restart it. Jupyter is a fantastic exploration and academic tool, but the fact that you can explore data is where the similarity stops with Zerve. No matter the bells and whistles that have been added to new cloud notebooks, they all share the same architectural flaw that makes them unsuitable for serious work.
The main innovation made by these tools is that they are cloud based, which makes collaboration easier. With these sorts of tools, it’s straightforward for an entire team to login to the same notebook and potentially run code and collaborate on a project together.
Unfortunately, this actually makes these environments even more unstable. Because of the global variable space of these tools, having multiple people all able to run code at the same time means that notebooks are constantly being put into a bad state, with kernels constantly needing to be restarted. In other words, innovation in the notebook space is moving in the wrong direction.
Zerve, on the other hand, has no restart kernel button because it’s impossible to get a Zerve canvas into a bad state. Zerve is guaranteed to produce a consistent result no matter how the code is executed. Whether in a single or multiplayer mode, this changes everything.
Benefit: True collaboration
Supposedly collaborative notebook environments have been around for years, and really all the “innovation” happening in the notebook space involves collaboration in one way or another. Anyone who has used a collaborative notebook knows that the experience is pretty terrible. Because notebooks are brittle, having multiple users accessing the same notebook at the same time presents a number of problems that are extraordinarily difficult to solve given the architectural flaws with Jupyter.
In Zerve, though, the collaboration is real-time and doesn’t present these same challenges. Users can run as many blocks of code as they want at the same time, write in multiple languages simultaneously, leave comments and tag one another, and more. Because of Zerve’s architecture, none of these activities poses any problem to stability, and with our upcoming GitHub integration, version control and change management is easy.
Benefit: Language Interoperability
Bouncing between tools is second nature to most data scientists and data engineers. SQL, R, and Python are written in different environments. It is our view however, that the need to do this, should be alleviated. The architectural flaws that exist in Data Science Development tooling here means the best that can be offered is to translate with packages like reticulate. This tends to be an offputting experience, and as a result an R coder just codes in Python, even when their skillset or the problem they are looking to solve, may be more suitable to R.
Because of the way that Zerve serializes the data from an executed block, different languages are suddenly able to utilize the same basic data types at the same time in the same project. For example, data frames are serialized as parquet files, so SQL, R, and python are all able to interact with these objects without having to do any complex and fragile code conversions. For v0.1, Zerve has built the architecture for mixing & matching languages, but certain aspects are still in our alpha process, if you’d like early access, please email info@zerve.ai
In Zerve, data/ML engineers, R users, and python users can develop in the same environment at the same time. We think this is very cool.
Benefit: Seamless multi-processing
Parallelizing code execution can be a complicated process that most coding tools are not designed to handle without specific, detailed instructions. If you’re training 5 different models, most people will just allow them to train in sequence rather than go through the trouble of parallelizing the compute. Given the availability of cloud compute, this inefficiency is pretty alarming.
Zerve’s serverless technology allows users to run as many code blocks at the same time as needed. That means that cloud compute costs only accrue when code is actually running and there’s no need to worry about remembering to shut down servers. Zerve handles the orchestration flawlessly, saving both compute costs and clock time.
Benefit: Persistent artifacts
Moving a model from the design and development phase to production is a challenging task. Many new companies have sprouted up in the last few years around MLOps and hosting and maintaining models in production, and many companies have built their own procedures and pipelines for deploying their AI solutions. Things like managing dependencies and hosting models are outside the scope of knowledge of many data scientists.
Zerve’s automatically serializes all of the artifacts of every analysis by default. That means that the models and data sets created in a project are accessible from elsewhere in Zerve and from external applications as well.
Start building in Zerve today!
Zerve is free to use and our free plan includes significant storage and compute resources. It’s perfect for code-first data users. Whether you’re querying a database with SQL, visualizing data with R, or deploying models in python, Zerve can enhance your workflow, increase your productivity, and enable you to collaborate with friends and colleagues on all of your data projects.
Sign up to use Zerve for free today as well as join our community channel here
Published: January 30, 2024
Written by: Phily Hayes
Subscribe to our newsletter: