Blog
Read Zerve’s articles and latest industry news and trends.Hackathon
Software Engineering Students Shine at Zerve Hackathon
A recap of the winning submission in Zerve's recent Hackathon, where some very talented students from the University of Limerick’s Immersive Software Engineering program took part
Written by: Phily Hayes, June 23, 2024

University of Limerick’s Immersive Software Engineering Students Shine at Zerve Hackathon
A couple of weeks ago, a group of incredibly talented students from the University of Limerick’s Immersive Software Engineering program showed off their innovative skills at the Zerve Hackathon. The course was divided into teams and each team demonstrated exceptional creativity and technical skills, with one team ultimately taking home the top prize.
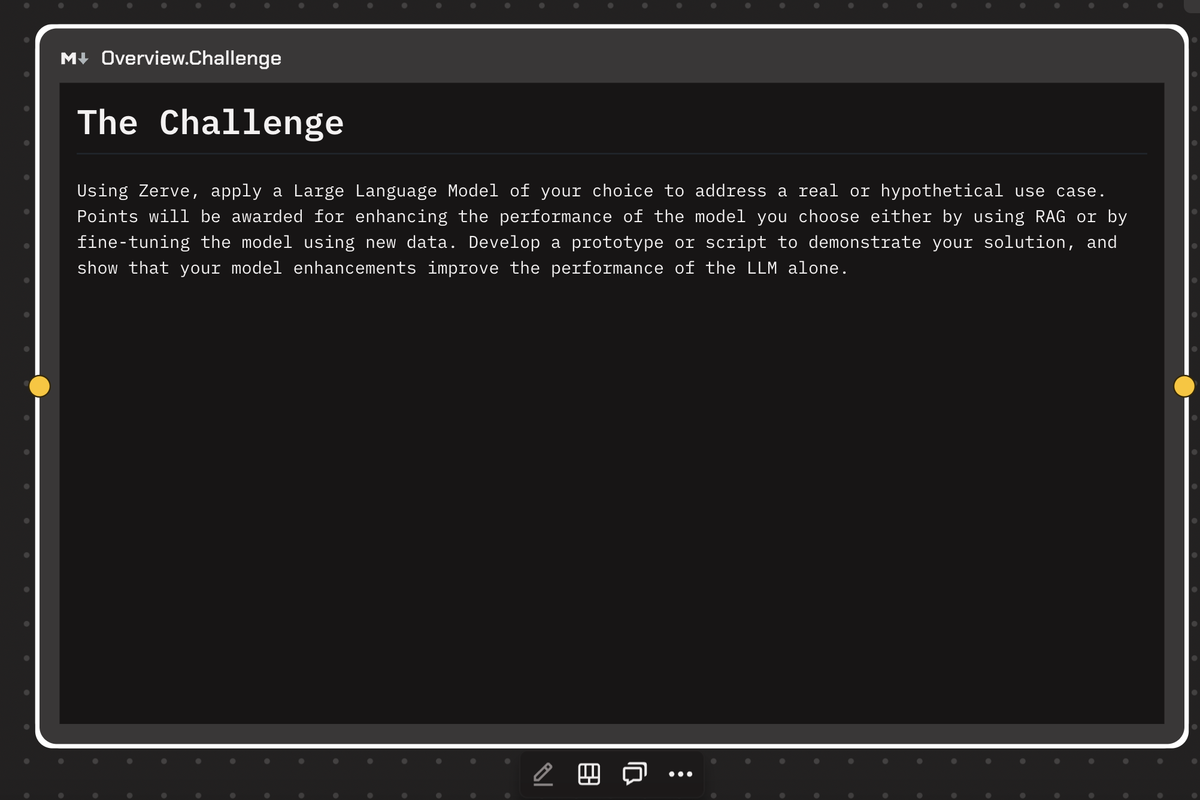
The Challenge
The hackathon, hosted by Zerve, posed a unique challenge to participants: using Zerve, participants applied a Large Language Model (LLM) of their choice to address a real or hypothetical use case. Points were awarded for enhancing the performance of the chosen model either by using Retrieval-Augmented Generation (RAG) or by fine-tuning the model using new data. Teams had to develop a prototype or script to demonstrate their solution and show that their model enhancements improved the performance of the LLM alone.
The Winning Solution: Dionysus - The God of Entertainment
The winning team from the University of Limerick impressed judges with their project, Dionysus - The God of Entertainment. This innovative solution aimed to perform feature extraction to find the key characteristics of a piece of media, and find the types of audience who would most resonate with this media.
1. Initial Approach with Claude3:
- The team started by using Claude3 alone to generate recommendations based on user input. For example, they asked for recommendations for people who like "Dune."
- The results were uninteresting and repetitive, as they mostly suggested "Dune" itself, highlighting the need for a different approach.
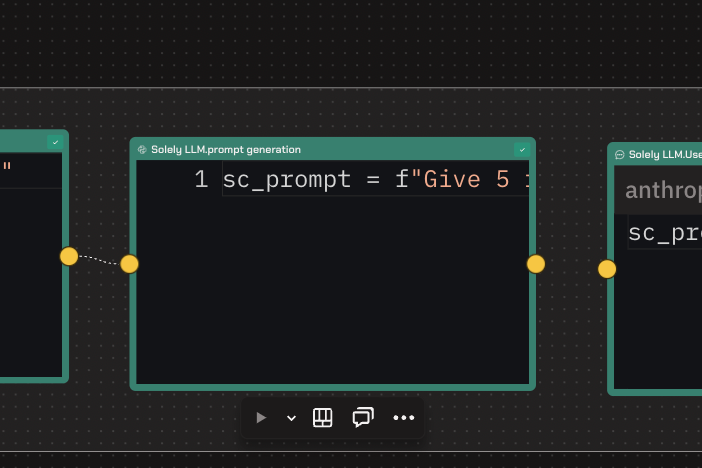
2. Implementing RAG:
- To enhance their solution, the team decided to use RAG (Retrieval-Augmented Generation).
- They incorporated several APIs to fetch trending data, including a trending movies API, trending TV shows API, NYT Best Seller API, and Spotify podcast API.
- This external data was used to enrich the LLM prompts, ensuring more diverse and relevant recommendations.
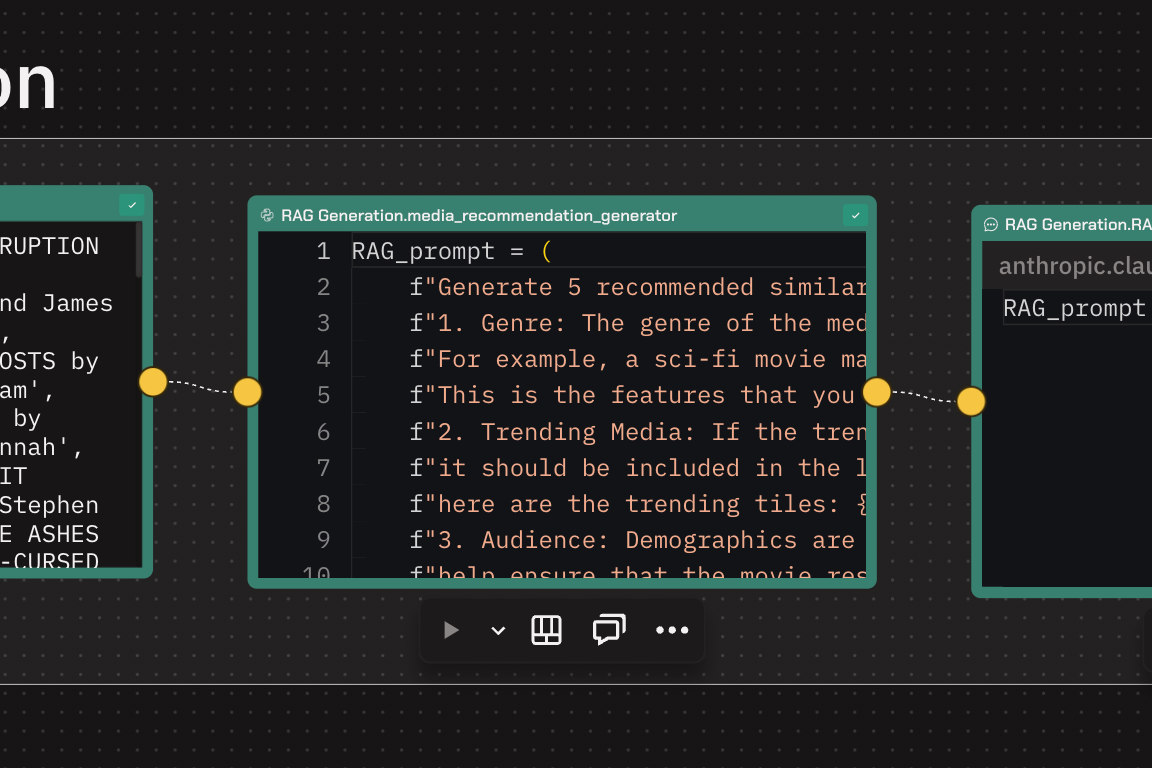
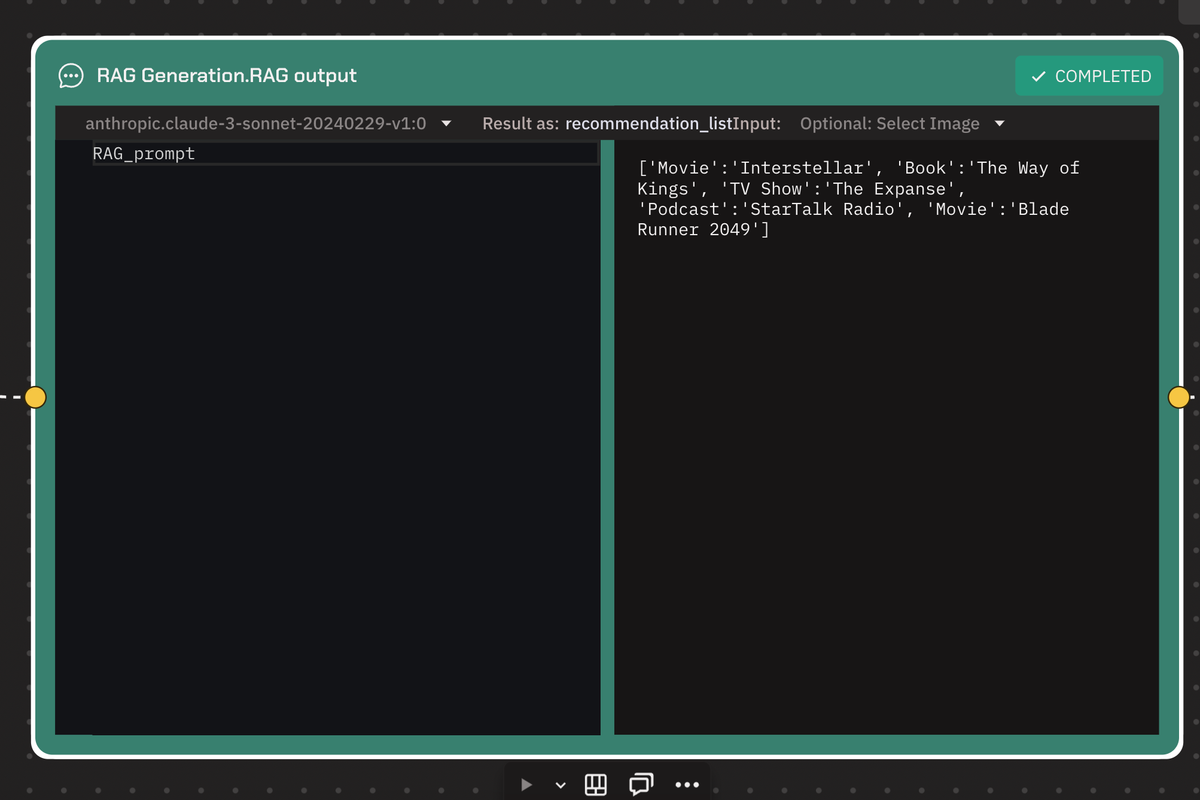
3. Generating Enhanced Recommendations:
- With the additional data from the APIs, the team created prompts that included genre and other characteristics of the media.
- For instance, they generated prompts asking for five recommended pieces of media similar to "Dune," based on specific features.
- This approach yielded more interesting and relevant results, providing diverse recommendations related to "Dune."
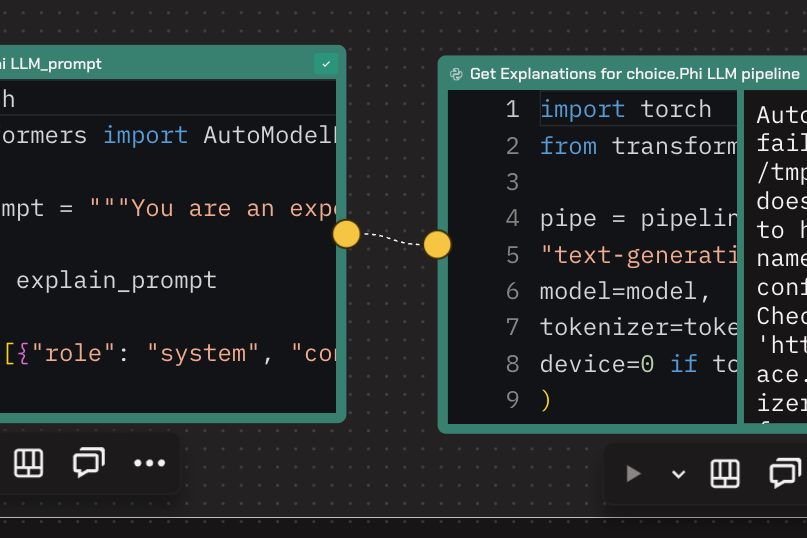
4. Providing Explanations for Recommendations:
- To enhance the user experience further, the team generated explanations for why particular recommendations were made.
- They chose a model from Microsoft and fine-tuned it using additional data, leveraging GPUs provided by Zerve.
- This refinement improved the model's ability to produce accurate and insightful explanations, enhancing the overall recommendation quality.
5. Ensuring Data Security with Zerve:
- One advantage of using Zerve for this project was the ability to host the fine-tuned model within Zerve.
- This ensured that user prompts and data were not sent to third parties, protecting sensitive information and maintaining data security.
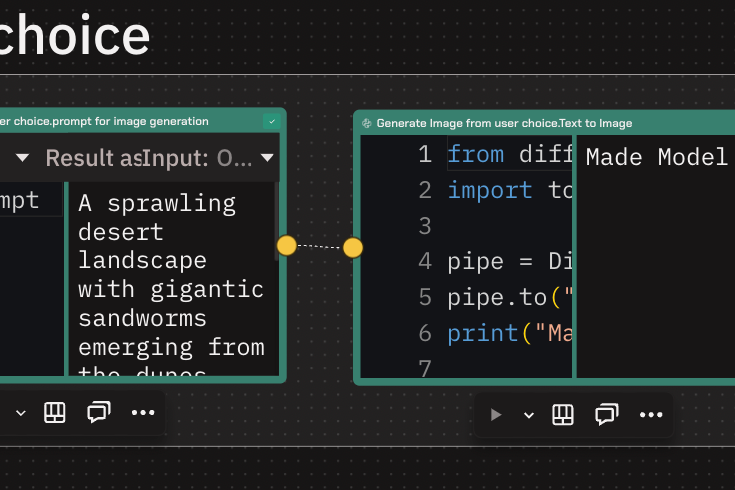
6. Creating Visual Enhancements:
- The final step involved creating a visual representation of the recommendations.
- The team used Claude 3 to generate prompts for an image generation AI, asking it to create images for the recommended media.
- These images were then produced by another LLM, adding a visual element that complemented the recommendations and rounded off the project nicely.
Enhancing LLM Performance
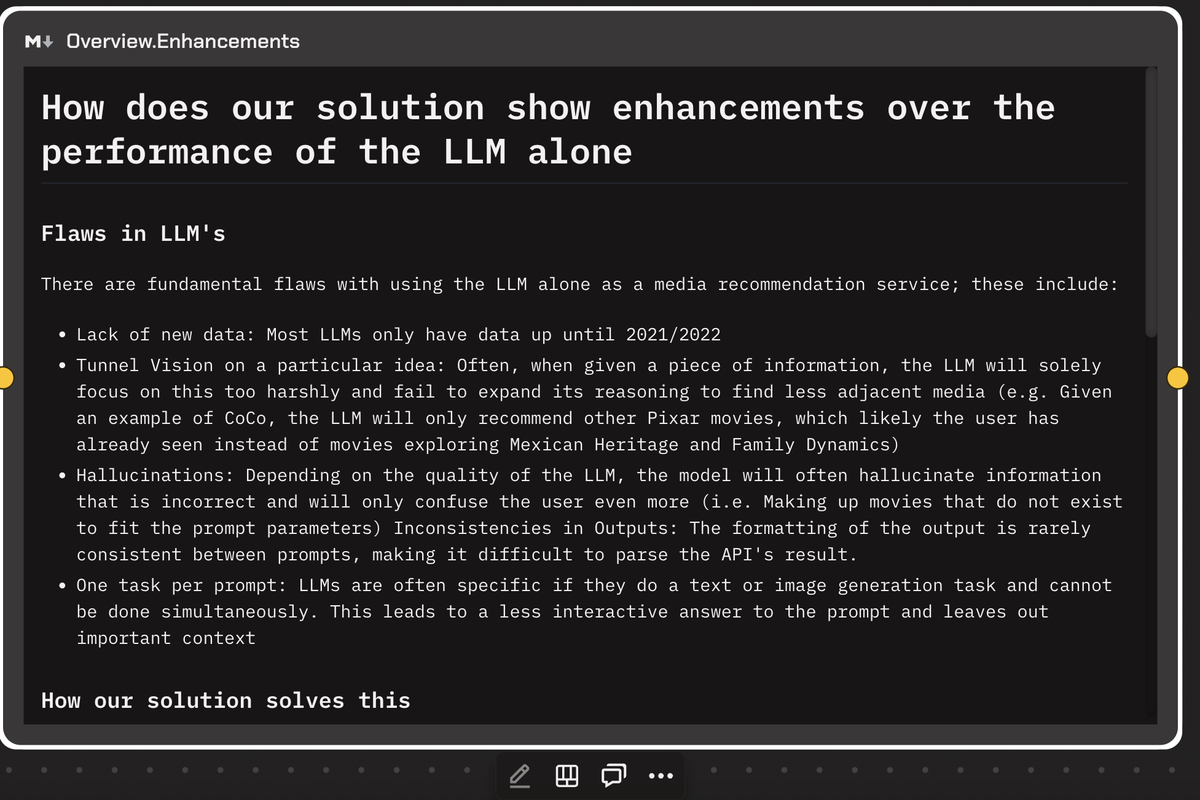
The team’s solution addressed several fundamental flaws commonly found in traditional LLMs used for media recommendations:
- Lack of New Data: Most LLMs only have data up until 2021/2022. By performing API calls to fetch current trending media, the solution ensured that recommendations were relevant and up-to-date.
- Tunnel Vision: Traditional LLMs often focus too narrowly on closely related media. Dionysus generates recommendations based on the features and themes of the media rather than just the title, providing more diverse and nuanced options.
- Hallucinations: LLMs sometimes produce incorrect or fictitious information. The solution grounded the LLM in reality by providing accurate data and employing specific prompts to reduce hallucinations.
- Discrepancies in Outputs: The formatting of outputs can be inconsistent. Dionysus provided clear instructions to the LLMs, ensuring reliable and consistent output formats.
- One Task per Prompt: Traditional LLMs can typically handle only one task at a time. The solution utilized parallel processes to generate images and text simultaneously, creating a more interactive and enriched user experience.
Conclusion
We were genuinely impressed by the quality of work and innovation demonstrated by all the teams that took part in the Zerve Hackathon. The winning project, Dionysus, not only showcased advanced technical skills but also a deep understanding of how to enhance large language models with real-time data and API integrations. The thoughtful approach and execution reflected their ability to tackle complex problems creatively and effectively. You can check out their winning submission for yourself right here.
We're excited to see what the future holds for these students, as their impressive performance at the hackathon suggests they have much to contribute to the field of AI.
Subscribe to our newsletter: