Blog
Read Zerve’s articles and latest industry news and trends.AI
Fine-Tuning Llama 3 in Zerve
Fine-tuning Llama 3 for a personalized tour guide in Italy
Written by: Jason Hillary, May 7, 2024

Fine -Tuning Llama 3 in Zerve
Introduction
In late April, Meta released Llama 3 and it quickly garnered attention for its enhanced capabilities in language understanding and generation. The model boasts substantial improvements, including a context length of up to 8,192 tokens, compared to 4,096 in Llama 2, but it also introduces a new tokenizer with a 128K-token vocabulary.
We thought it would be fun to leverage our Hugging Face integration in Zerve to import Llama3 into a canvas and fine-tune it to build a personalized travel itinerary for a trip to Italy. Because Zerve persists your models, variables and data in the canvas, once I import Llama3, or any other LLM, this becomes a fully hosted, accessible, private version of that model.
Understanding the Fine-Tuning Technique Used
In the journey of adapting Llama 3 to generate personalized travel itineraries, the fine-tuning approach employed here utilizes the model's pre-trained capabilities augmented by custom input prompts. This technique is less about traditional fine-tuning—where the model's weights are extensively retrained—and more about leveraging the model's existing knowledge base, applying specific prompts to guide the generation process.
This method can be seen as "light" fine-tuning or prompt engineering, where the goal is to tailor the AI's responses to detailed user queries through smart input manipulation. It is particularly effective when the pre-trained model already possesses a substantial understanding of the content domain, allowing for refined output tailored to specific requirements without the need for deep, computational retraining.
Technical Deep Dive: Fine-Tuning Llama 3 on Zerve
In this section, we explore the technical details of fine-tuning Llama 3 using a custom-built scenario as a tour guide in Italy. The code snippet below shows how I utilized Zerve's capabilities to adapt Llama 3 for generating personalized travel itineraries.
Code Initialization and Setup
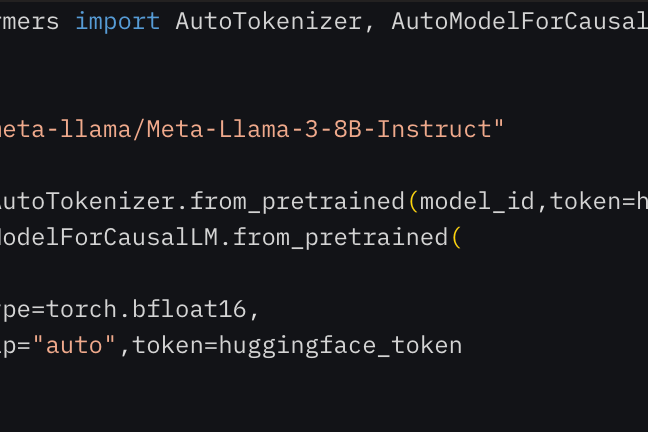
Firstly, I initialized the tokenizer and model using the AutoTokenizer and AutoModelForCausalLM classes, setting up the model with optimized configurations for the task.
Data Preparation
I then prepared the input by setting the context and a complex user query for a three-week tour in Italy. This setup illustrates how to personalize responses based on user input.

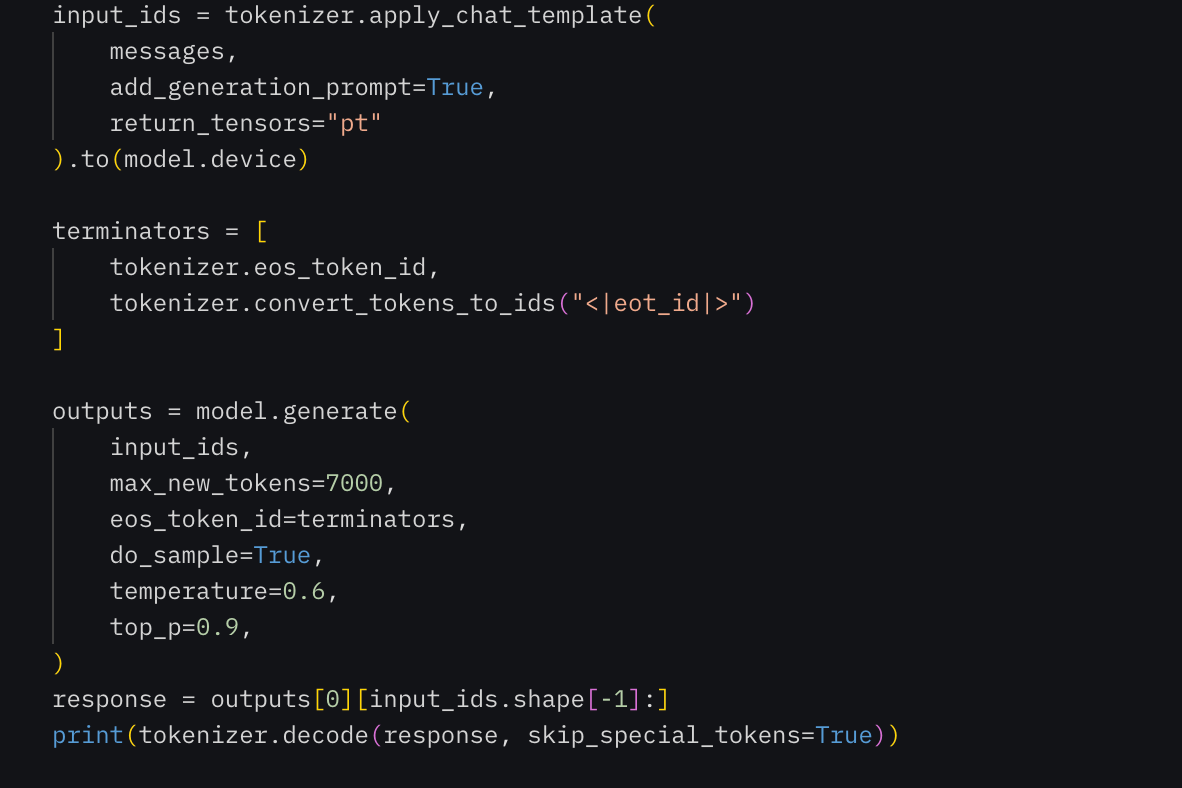
Generating Response
I used the model's generate function to produce a detailed itinerary, showcasing the model's ability to handle nuanced tasks.
GPU Infrastructure
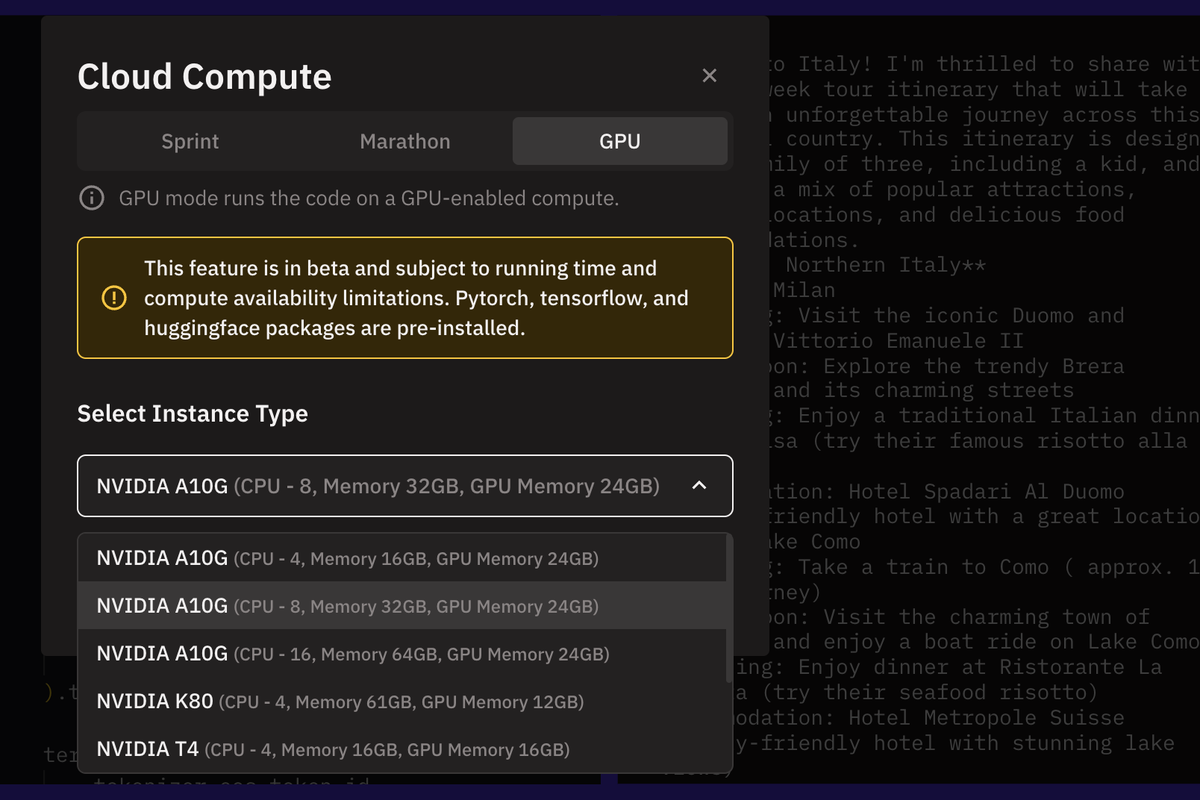
Using Zerve’s IDE, I was able to run serverless GPUs without having to worry about managing the complex infrastructure. At code block level, I selected the relevant GPU I wanted to use, and also had the option for CPUs and lambdas for other code blocks if necessary.
Results
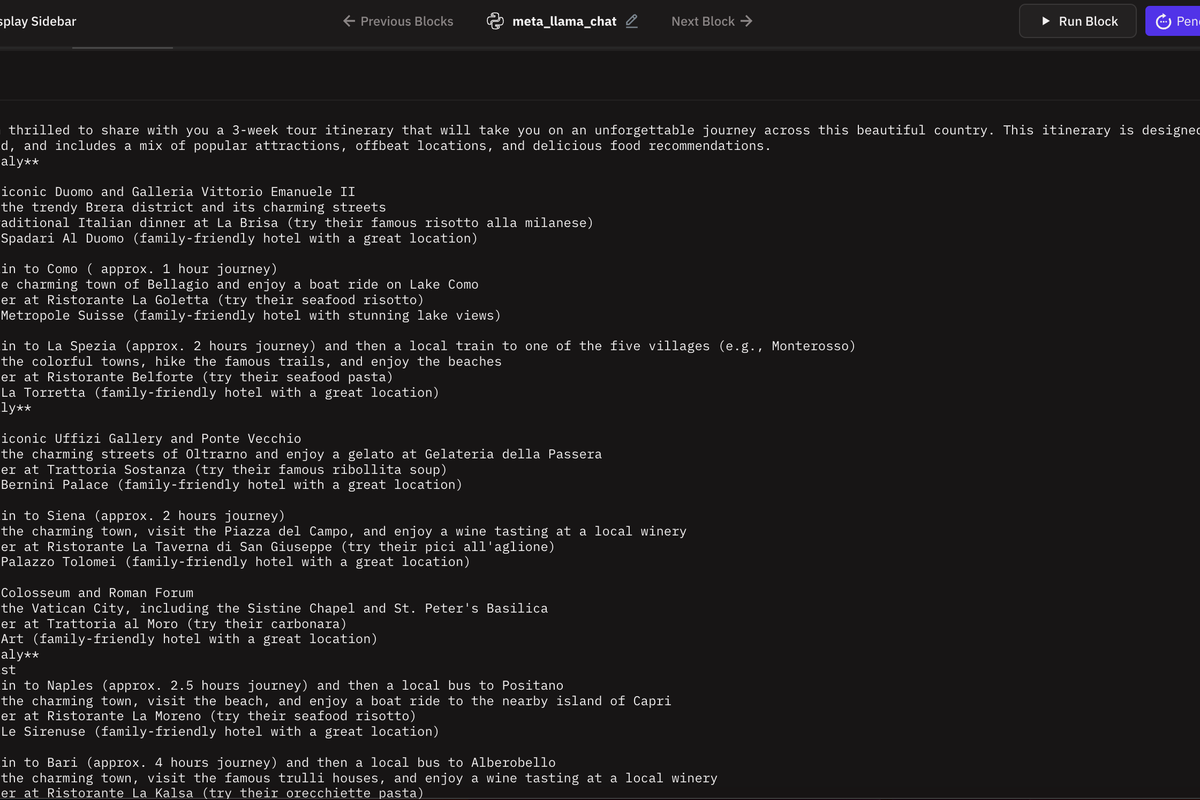
The results generated a tour itinerary for a family of three travelling across Italy, with locations to visit, daily plans as well as recommendations on where to stay and what to eat.
Efficiency and Privacy
While my travel plans on a trip to Italy would not exactly be classified as sensitive data, because Zerve is self-hosted through AWS, had I wanted to expose Llama 3 to any sensitive data, I could do so with ease from the safety of my own, private cloud infrastructure. This addresses a major privacy concern of many businesses around sensitive data leaking to third party prompts when fine-tuning these models in other environments.
Conclusion
Diving into fine-tuning Llama 3 using Zerve turned out to be an intriguing venture. It was cool to see how we could nudge a high-powered model like Llama 3 to generate personalized travel plans with just a bit of clever prompt engineering—no heavy lifting required in terms of retraining. Using Zerve's serverless GPUs, the technical process was streamlined, allowing me to focus more on the creative aspects of AI applications rather than getting bogged down by infrastructure management.
The final itinerary for a family trip across Italy was both detailed and thoughtful, suggesting neat spots to visit, cozy places to stay, and delicious local eats. Honestly, while the itinerary sounded like a dream vacation, I'd personally dial down the travel a bit for some extra relaxation time.
And with everything hosted securely on our own cloud through AWS, privacy concerns were the last thing on my mind, even when working with non-sensitive data. This project was a neat demonstration of how tailor-made AI applications can really shine, blending efficiency with a keen respect for user privacy.
Call to Action
You can check out the canvas and code for yourself by following this link. Feel free to comment or ask questions using comments in the canvas, we’d love to hear from you!
Subscribe to our newsletter: